Improving Regular Expressions with Typography
After the more abstract talk I’d like to come back to something concrete. Regular Expressions, or regex, are powerful but often inscrutable. Today let’s see how we could make them easier to use through typography and visualization without diminishing that power.
Regular Expressions are essentially a mini language embedded inside of your regular language. I’ve often seen regex written like this,
new Regex(“^\\s+([a-Z]|[0-9])\\w+\\$$”) // regex for special varsthen sometimes reformatted like this
//regex for special vars
new Regex(
“^” // start of line
+“\\s+” // one or more whitespace
+“([a-Z]|[0-9])” //one letter or number
+”\w+” // one word
+”\\$” // the literal dollar sign
+”$” // end of line
)The fact that the author had to manually split up the text and add comments simply screams for a better syntax. Something far more readable but still terse. It would seem that readability and conciseness would be mutually exclusive. Anything more readable would also be far longer, eliminating much of the value of regex, right?
Au contraire! We have a special power at our disposal: we can render whatever we want in the editor. The compiler doesn’t care as long as it receives the description in some canonical form. So rather than choosing readable vs terse we can cheat and do both!
Font Styling
Let’s start with the standard syntax but replacing delimiters and escape sequences with typographic choices. This regex looks for variable names in a made up language. Variables must start with a letter or number, followed by any word character, followed by a dollar sign. Here is the same regex using bold italics for all special chars:
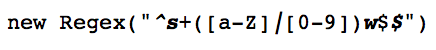
Those problematic double escaped backslashes are gone. We can tell which dollar sign is a literal and which is a magic variable thanks to font styling.
Color and Brackets
Next we can turn the literals green and the braces gray, so it’s clear which part is actual words. We can also replace the $ and ^ with symbols that actually look like beginning and ending of lines. Open and close up brackets or floor brackets.

Now one more thing, let’s replace the w and s magic characters with something that looks even more different than plain text: letter boxes. These are actual unicode characters from the "Unicode Characters in the Enclosed Alphanumeric Supplement Block".

Now the regex is much easier to read but still compact. However, unless you are really familiar with regex syntax you may still be confused. You still have a bunch of specific symbols and notation to remember. How could we solve this?
Think Bigger
Let’s invent a second notation that is even easier to read. We already have a clue of how this should work. Good programmers write the regex vertically with comments as an adhoc secondary notation. Let’s make it official.
If we have two views then the editor could switch between them as desired. When the user clicks on the regex is will expand to something like this:
We get what looks like a tiny spreadsheet where we can edit any term directly, using code completion so we don’t have to remember the exact terms. Furthermore the IDE can show the extra documentation hints only when we are in this "detailed" mode.
Even with this though, there is still a problem with regex. Just by looking at it you can’t always tell what it will match and what it won’t. Without a long comment, how do programmers today know what a regex will match. They use their brains. Yes, they actually look at the text and imagine what it will match in their heads. They essentially simulate the computer the regex mentally. This is totally backwards! The whole point of a computer is to simulate things for us, not the other way around. Can’t we make the computer do it’s job?!
Simulate
Instead of simulating the regex mentally, let’s give it some strings and have the computer tell us what will match. Let’s see what that would look like:

We can type in as many examples as we want. Having direct examples also lets us test out the edge cases, which is often where regexes fail.
Hmm. You know… this is basically some unit tests for the regex. If we just add another column like this:

then we can see at a glance if the regex is working as expected. In this example the last test is failing so it is highlighted in red.
Most importantly, the unit tests are right next to the regex in the code; right where they are used. If we collapse the triangle then everything goes away. It’s still there, just hidden, until we need it.
This is the power of having a smart IDE and flexible syntax. Because these are only visualization changes it would work with any existing compiler. No new language required.
Posted September 15th, 2014
Tagged: programming fonts