Why you can’t build a web browser and why you should anyway.
In the last couple of years I’ve seen a lot of lamenting about the browser mono-culture. I even wrote about it myself. Some complains focus on how complicated the web specs have become. So big that only a few companies can implement a browser from scratch. I think these complaints are misplaced. Even if the web platform didn’t have such a large API surface it still wouldn’t matter. You can’t build a large scale browser with large marketshare. The browser market would still be a monoculture. You can't solve a business problem with a technology solution. I also don't think that replacing the web with something smaller like Gemini is the answer.
But you know what? We should build new browsers anyway! And to prove it I just made one in less than 1000 lines of code! Let's dive in.
No One Can Build a Browser
WebKit vs Chromium. Firefox is the last independent browser. Blah blah blah. This is a lot of whining without getting to the root cause. Yes, no one can make a new browser anymore, but so what? No one but a few people invest in building a new browser because there is no motivation for it unless you control the OS or a search engine. There is no money in the browser itself. WebKit is driven by Apple's Safari team which is driven by the selling of Mac hardware. Chromium is driven by the Chrome team which is driven by Google’s search engine. Of course no one can build a new browser.
Building a browser means you're competing with two of the richest companies in the history of the world. Of course they are the only ones who can invest billions in a commodity product that has no direct revenue. Even Microsoft couldn’t do it; Edge is their Hail Mary Pass to not be displaced on their own platform. Even if somehow you could make a new full spec browser it still wouldn’t matter because you’d never get marketshare from the platform owners controlled by, again, some of the largest companies ever. Even if you win you’d lose.
Side note: When I was at Mozilla I urged senior management to switch the desktop browser to WebKit (to lower costs since no one cares what the engine is) and focus on bringing FF to new platforms (like standalone VR headsets).
The Problems with a Browser Monoculture
So yeah, no one can build a browser. No one can start from scratch and keep up with Apple & Google. Even Microsoft couldn’t. But why does this matter?
First, it's a problem because it hinders development of alternative operating systems. A new OS isn't usable in the modern would without a full spec browser. It's the same issue as launching an OS without an existing App Store. Embracing the smol web or creating new protocols won’t fix any of these issues. Building a new browser won't help. This is a real problem, I agree. It does stop new platforms from emerging because the platform under you is always an intermediator. This is one reason why Facebook has invested so much in VR and doesn't use the Chrome browser on the Quest.
We will never beat the browser makers at their own. Let’s play a different game instead. Let’s go back to the beginning and think smol
Gemini?
I like the idea of the SMOL web and Gemini. But I think their approach is wrong. The Gemini protocol throws the baby out with the bathwater. It doesn't even allow anchors so you can jump to a specific part of a document. This was a feature of the very first version of the web back in the mythical golden days that the SMOL web longs for.
In the Gemini FAQ they say: Why not just use a subset of HTTP and HTML?
The problem is that deciding upon a strictly limited subset of HTTP and HTML, slapping a label on it and calling it a day would do almost nothing to create a clearly demarcated space where people can go to consume *only* that kind of content in *only* that kind of way.
I agree that this is Solutionism at it’s worst.The Gemini protocol is really beside the point. What matters is creating a part of the Internet where tracking and spam are not possible. The Gemini community is enforcing this with a protocol, but it’s the tracker-less part of the web that is the point. That's where the value is.
I like Gemini's goal, but it has problems. First, it’s exclusionary. By making it different it becomes harder to get there. The Gemini part of the Internet will always be insular and separate. Second, it doesn’t solve any real problems. It doesn’t address the reasons The Web became a cess pool of spam like this in the first place. Essentially Gemini is giving up on the world and saying "We'll just move elsewhere and build our own tiny web without you!" Fine if you want that, but it’s awfully depressing and unproductive. I don’t think it actually helps anyone.
Ultimately Gemini isn’t really a technology or protocol, it’s a social statement. It’s about building a community that says "no tracking and spam is tolerated here", and they are using the protocol to enforce this. I like it. I just think there’s more we could do that would reuse existing technology in better ways, and benefit more people.
Let's Build a Browser Anyway
The Gemini FAQ claims that their spec is easy enough to implement in 50 to 100LOC. I don’t know if that’s a good metric. Certainly HTML & CSS is more complicated, but it’s not that much more complicated. I've found that a lot of things that seem hard or impossible become solvable or even easy if you are willing to relax your constraints.
- A high performance Javascript VM: hard. A slow JS interpreter: easy.
- A full spec compliant PDF parser. hard. A PDF 1.1 parser (which is the parts most people want), far easier.
To prove this point I wrote a browser implementation in less than 1000 lines of code. (I was shooting for 500 lines, but currently I’m stuck around 750). Here’s what it looks like:
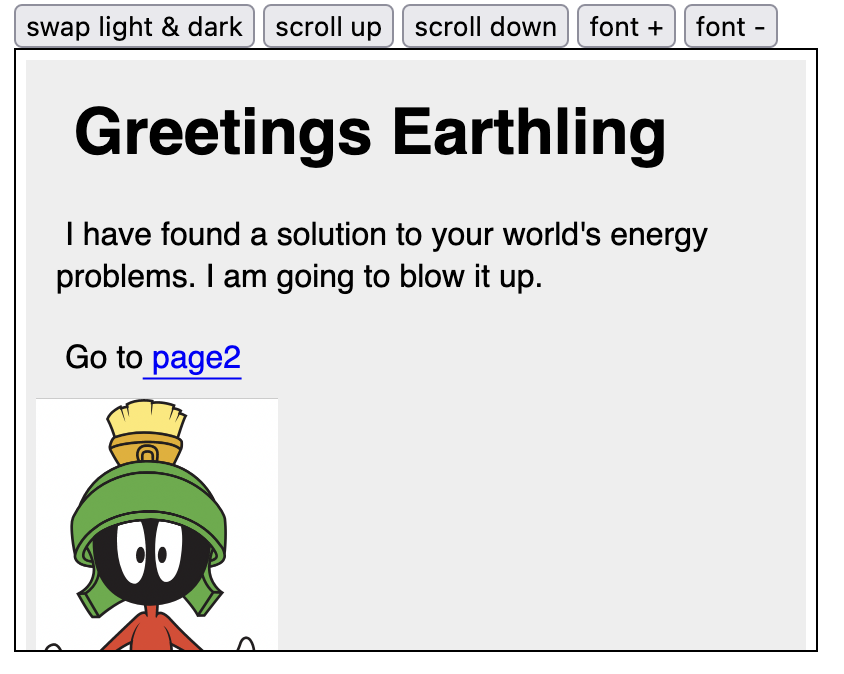
This is 750 LOC of typescript. The parsers for HTML and CSS are not spec compliant, but they do handle a useful subset and each is tiny! I mean tiny on the order of 20 lines for the grammar thanks to the magic of OhmJS, a PEG toolkit. This prototype example was not meant to actually be a usable browser, but to prove that it can be done.
My mini browser really does parse and render HTML and CSS the way it would have been done 15 years ago. It has links, lists, paragraphs and images. It supports basic CSS properties and the cascade. It does not support all of the CSS spec, but it is written in such a way that it would be clear where you could add them.
Okay, I’m sort of cheating a bit because I did it in a browser, but it’s not that much of a cheat. The only thing I’m using from the host browser is the graphics and network layers, both of which a standalone app would leverage the OS for anyway, so I think it’s fair. The implementation is simple enough that I could see this ported to something like a Raspberry Pico (not a Pi, a Pico) with a bit of supporting C/C++/Rust code.
And yes it has some rendering glitches. I said it works, not that it’s bug free. But this proves that in a thousand lines of code we can make something that can actually browse the web. And if I could get this far in less than a thousand lines of Typescript, what could be built with 10k of Rust code? You could have a very fast and lean browser that provides real value for a lot of people. It could even support images and video links *without* including Javascript support. (The audio and video elements are a thing for a reason).
Uses for a smaller independent Web Browser engine
Is it possible to make a new full browser that is so complete it can run Facebook or Google docs? No. We'd need to fork an existing engine for that. But, can you make a browser that is useful? Yes! There’s lots of the web you can render. The web standards are designed to degrade gracefully. Just because most pages use JS doesn’t mean the browser has to render it. The Web !== React SPAs. There’s so much more.
- A new lightweight browser that’s a full native desktop app with zero JS support. It would be *fast* and use very little memory. It could even run on retro computers.
- A replacement for Electron that includes the styling and layout parts of the web without the mess that overhead of a second runtime.
- a library for building News and feed readers.
- In game rendering of 2d rich text and images (think catalog and in game news updates)
- PDF generation
- local app development. Imagine how much faster Electron could be if it didn’t need to support every possible browser API?
- offline bookmarks reader
- eBook renderer
- web browser or UI for tiny embedded systems like a Raspberry Pico
- A knowledge archive app
Such a browser should focus on speed and new uses. It should focus on good experiences. When you need a real browser for something, then just open a call out to the user’s preferred full browser.
The Web Scales Down Too
We must remember that the web was designed to scale. Just because the spec details it doesn’t mean you have to implement it. From the very beginning graceful degradation was a key value point of The Web. You can make a mini browser. It doesn’t have to be fully compliant to be useful. There’s a tons of things you could do with a browser that isn’t spec complaint. In fact, without any JS support at all (which cuts out probably 75% of what a full browser does).
I hope this little prototype inspires you to go build something amazing.